| automatische
SourceCode Generierung |
|
einer einfachen Association |
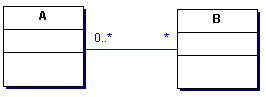
|
|
Die unscharfe Definition von UML
zeigt sich vor Allem bei der automatischen Sourcecode- Generierung aus
vorhandenen UML Diagrammen. Das triviale nebenstehende UML Klassendiagramm
wird von den UML Tools in verschiedenen Sourcecode umgesetzt.
|
public class A {
}
public class B {
/**
* @clientCardinality
*
* @supplierCardinality
0..*
*/
private A lnkA;
}
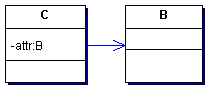
|
|
Von Together V6 erzeugt:
-
Beim modellieren der Assoziation
wurde bei B begonnen, deshalb hat Together für die Klasse A gar keinen
Sourcecode generiert. Die Assoziation ist von A aus nicht zu erkennen.
-
Bei Klasse B hingegen wurden Kommentarzeilen
eingefügt.
-
Eigenartig ist die Definition "private
A linkA;", denn diese ermöglicht nur
die Speicherung genau eines Objekts A, im UML Modell wurden jedoch 0..*
modelliert.
-
Zudem ist die Assoziation vom Namen
des Attributes abhängig. Beginnt dieser mitl lnk (z.B. lnkA)
so wird obiges Bild erzeugt, beginnt dieser nicht mit lnk (z.B.
attr), so wird linkes Bild erzeugt, insbesondere wird das Attribut im Klassenmodell
angezeigt.
|
public class A
{
public B theB[];
public A()
{ }
}
public class B
{
public B()
{ }
}
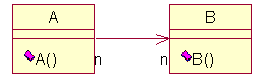
Nach dem Reverse Engineerung (Einlesen des Source in Rose):
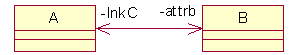
|
|
Von Rational Rose
Rose will keinen direkten Bezug zum Sourcecode haben.
Deshalb wird bei der Erstellung der UML Diagramme nicht automatisch Code
generiert. Es stehen Codegeneratoren zur Verfügung um Code-Grundgerüste
zu erzeugen und um vorhandenen Code einzulesen (Reverse Engineering)
-
Rose generiert für gerichtete Assoziationen ein Klassenattribut.
-
Die Multiplizität n (*) wir als Array übersetzt
(was auch nicht richtig ist, da Array eine feste Größe hat,
n jedoch unbestimmt ist).
-
Ist die Assoziation ungerichtet, so wird kein Klassenattribut
erzeugt.
-
Hinweis: Im Gegensatz zu den anderen Tools auf dieser Seite
wird die Sourcecodegenerierung bei Rose manuell angestoßen. Ein Live-Editieren
des Sourcecodes ist nicht vorgesehen (Rose versteht sich nicht als IDE
für die Programmerstellung, sondern als reines UML Tool)
-
Wird Sourcecode in Rose eingelesen, so werden die Attributnamen
als Rollenbezeichner verwendet.
-
Hier ist UML eventuell unübersichtlich, da die weiter
entfernte Rollenangabe ein Attribut der Klasse ist (z.B. attrb ist ein
private Attribut von A und lnkC ein private Attribut von B).
|
public class A {
Vector myB;
}
public class B {
@element-type A0..*
*/
Vector myA;
} |
|
Von Argo UML 0.10.1
Ganz anders wurde der Code von
ArgoUML generiert:
-
Die Klasse A hat auch eine Klasse B.
-
Die Klassen werden in Vector-Objekten
gespeichert, damit wird die 0..* umgesetzt.
-
Die (wohl falsche) @element Angabe
produziert nicht kompilierbaren Code.
|
public class A {
public Vector B = new
Vector();
}
public class B {
public Vector A = new
Vector();
} |
|
Von Poseidon V1.3
-
Ähnlich wie ArgoUML wird ein Vektor generiert und immerhin
gleich erzeugt (zudem ist der Code kompilierbar).
-
Bitte beachten: der Vektor hat zwar den Namen A (bzw. B),
jedoch keinerlei Bezug zu der Klasse. Im Vektor kann alles gespeichert
werden, es ist also Aufgabe der Programmlogik die UML Logik zu implementieren
(es erfolgt nicht automatisch!).
|
Fazit:
Man muss nicht verwundert sein,
dass UML noch nicht überall konsequent eingesetzt wurd. Es liegt an
der mangelhaften und unterschiedlichen Toolunterstützung. Wenn erst
das UML Modell modelliert wird, es aber nur in ein grobes Programmgerüst
umgewandelt wird, muss die Implementierung nochmals das UML Modell nachbauen.
Die Arbeit wird doppelt verrichtet und bewirkt doppelte Fehlerquellen!
Hierfür sind Abhilfen zu schaffen.
Vor Allem sind Einschränkungen und Modellierungsvorgaben für
UML Modelle aufzustellen
und zu beachten (QS-Regelungen, analog zu CodingRules für JAVA oder
C++).
|
|
|